
Mancala vs AI
We will be implementing popular search algorithm techniques in the popular game Mancala to maximize wins and draws.
What is Mancala?
According to Wikipedia, Mancala is a turn-based strategy game played with small stones, beans, or marbles, and rows of holes or pits. The objective of the game is to capture as many pieces as possible. The origin of the game dates back to the 3rd century with evidence of the game existing in Ancient Egypt.
There are many different ways to play this game, with varying setups and rules, so the ones we'll be following will be listed below:
- Players sit on opposite sides of the long edge of the board.
- There are 6 small pits in the middle of the board and 2 large ones at the end. The large pits at the end of the board and to the right of the players are their Mancalas.
- Each pit (excluding the Mancalas) are populated with 4 stones each.
- On every turn, select a pit on your side of the board which contains one or more stones, then distribute its stones, one stone per pit, in a counter-clockwise direction until no stones are remaining.
- If you encounter your opponents mancala, skip it
- If you encounter your own mancala, place one stone into it
- If the last stone lands in an empty pit on your side, capture all stones in your opponent's pit on the opposite side of the board as well as the stone you just dropped into the empty pit, and place it in your Mancala.
- If either player's pits are entirely empty (excluding the Mancalas) the game is over.
- The player who still has stones on their side of the board collects all of the stones and places that into their Mancala.
- The player with the most stones in their mancala is the winner. If there is an equal number of stones in both players mancala, the game ends in a tie.
If the last stone you drop is in your own mancala, take another turn immediately11
There are additional rules that can be played, and an entirely different set of rules, but for now, this is the basic version of Mancala we will implement.
Implementation
All the code for this specific Mancala implementation can be found here. You can skip this section if you just want to read about the algorithms we'll be using.
Implementing this is straightforward for the most part. We are not very concerned with a GUI for this per se, so a TUI will do. Let's start by initializing the Mancala class:
class Mancala:
def __init__(self, pits_per_player=6, stones_per_pit=4, print_output=True, continue_turn=False):
self.pits_per_player = pits_per_player
# Initialize each pit with stones_per_pit number of stones
self.board = [stones_per_pit] * ((pits_per_player + 1) * 2)
self.players = 2
self.current_player = 1
self.moves = []
self.p1_pits_index = [0, self.pits_per_player - 1]
self.p1_mancala_index = self.pits_per_player
self.p2_pits_index = [
self.pits_per_player + 1, len(self.board) - 1 - 1]
self.p2_mancala_index = len(self.board) - 1
self.p1_win = 0
self.p2_win = 0
self.draw = 0
self.print_output = print_output
# winning advantage
self.first = 0
self.wins_w_first = 0
# Zeroing the Mancala for both players
self.board[self.p1_mancala_index] = 0
self.board[self.p2_mancala_index] = 0
# Continue turn after stone dropped into mancala
self.continue_turn = continue_turn
Most of the parameters are self explanatory. For the actual board, we specify the board size and mancala indices, as well as how many stones can go in each pit. We also establish the amount of players, and calculate the wins and loses of each of them. Since we are trying to pit two AIs against each other, we should specify which AI wins (using Player 1 and Player 2) as well as establish who wins first.
Overall, it's a really messy class that can (and should) definitely be refactored at some point22, but it works so we'll go with that.
Displaying the board
Now let's create a visual of the game. To display the board, we use this function below to create a TUI for the Mancala board:
def display_board(self):
"""
Displays the board in a user-friendly format
"""
player_1_pits = self.board[self.p1_pits_index[0]:self.p1_pits_index[1] + 1]
player_1_mancala = self.board[self.p1_mancala_index]
player_2_pits = self.board[self.p2_pits_index[0]:self.p2_pits_index[1] + 1]
player_2_mancala = self.board[self.p2_mancala_index]
print('P1 P2')
print(' ____{}____ '.format(player_2_mancala))
for i in range(self.pits_per_player):
if i == self.pits_per_player - 1:
print('{} -> |_{}_|_{}_| <- {}'.format(i + 1, player_1_pits[i], player_2_pits[-(i + 1)], self.pits_per_player - i))
else:
print('{} -> | {} | {} | <- {}'.format(i + 1, player_1_pits[i], player_2_pits[-(i + 1)], self.pits_per_player - i))
print(' {} '.format(player_1_mancala))
Which should look like this:
P1 P2
____27____
1 -> | 0 | 2 | <- 6
2 -> | 0 | 0 | <- 5
3 -> | 0 | 0 | <- 4
4 -> | 0 | 2 | <- 3
5 -> | 0 | 2 | <- 2
6 -> |_1_|_1_| <- 1
13
Playing the game
There are several things to consider to implement an agent that plays Mancala. These things are:
- Defining what a valid move is
- Giving the AI a list of valid moves it can make
- Capturing stones as a valid move if it's possible
Selecting a valid pit boils down to selecting one of your pits (not the opponents or the mancalas). We can check if it's a valid move by using function below33:
def valid_move(self, pit): # actions
return True if pit in range(1, self.pits_per_player+1) else False
Now we can define valid moves or actions that the AI can take:
def actions(self):
valid_pits = []
if self.current_player == 1:
for pit in range(1, self.pits_per_player + 1):
board_index = pit - 1
if self.board[board_index] > 0:
valid_pits.append(pit)
else:
for pit in range(1, self.pits_per_player + 1):
board_index = self.p2_pits_index[0] + (pit - 1)
if self.board[board_index] > 0:
valid_pits.append(pit)
return valid_pits
This function basically takes the range of the player's pits and checks to see if that pit has stones in it or not. If it does, it adds that pit to the list of valid moves. Then it returns that list so that the AI can make a choice.
Capturing stones is a tricky function because three things must exist to capture stones:
- The pit you place the last stone in must be on your side
- The pit you place the last stone in must be empty
- The pit opposite the pit that the last stone was placed in must have stones available to capture44
This function would look something like this:
def capture_stones(self, current_index):
if self.current_player == 1:
if (current_index >= self.p1_pits_index[0] and
current_index <= self.p1_pits_index[1] and
self.board[current_index] == 1):
opposite_index = self.p2_pits_index[1] - \
(current_index - self.p1_pits_index[0])
if self.board[opposite_index] > 0:
captured = self.board[opposite_index] + \
self.board[current_index]
self.board[opposite_index] = 0
self.board[current_index] = 0
self.board[self.p1_mancala_index] += captured
else:
if (current_index >= self.p2_pits_index[0] and
current_index <= self.p2_pits_index[1] and
self.board[current_index] == 1):
opposite_index = self.p1_pits_index[1] - \
(current_index - self.p2_pits_index[0])
if self.board[opposite_index] > 0:
captured = self.board[opposite_index] + \
self.board[current_index]
self.board[opposite_index] = 0
self.board[current_index] = 0
self.board[self.p2_mancala_index] += captured
We first check which player we are, then we can check to make sure that the pit is on our side, finally we can capture the stones on our opponents side if they have any in there.
We can now set up the basic play function. One turn in Mancala would go like this:
- Choose a pit to distribute the stones from
- Distribute stones in a counter-clockwise motion
- Check for captures
- Switch players
Implementing these rules into a massive play function would look like this55:
def play(self, pit): # result
if pit is None:
return self.board
if not self.winning_eval():
if self.print_output:
self.print_moves(pit)
current_index = self.get_pit_index(pit)
if not self.valid_move(pit):
if self.print_output:
print("INVALID MOVE")
return self.board
stones = self.board[current_index] # get amount of stones
self.board[current_index] = 0 # remove stones
opponent_mancala = self.p2_mancala_index if self.current_player == 1 else self.p1_mancala_index
while stones > 0:
current_index = (current_index + 1) % len(self.board)
if current_index == opponent_mancala:
continue
self.board[current_index] += 1
stones -= 1
self.capture_stones(current_index)
self.continue_play(current_index)
self.moves.append((self.current_player, pit))
return self.board
AI Agents
Now that the game has been fully implemented, we can simulate agents playing the game. For a quick definition, an agent is a program that can interact with its environment. Think of it like the human brain cells that play doom in a petri dish. This Mancala agent will be able to move pieces, capture stones, and win/lose the game. There will be three strategies that the agents will be implementing:
- Random agent
- Minmax algorithm
- Alpha beta pruning algorithm
To figure out which strategy is the best, we will run 100 games of Mancala and see which agent wins the most out of them.
The random agent
This agent is purely random, choosing moves using Python's built in random module. We can define the random_move_generator with this function:
def random_move_generator(self):
valid_pits = self.actions()
if valid_pits:
return random.choice(valid_pits)
return None
When pitting the two agents against each other for 100 games, we get this output:
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 1 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P1 win %: 47%
P1 loss %: 47%
Avg turns per game: 22
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 2 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P2 win %: 47%
P2 loss %: 47%
Avg turns per game: 22
⊰ΞΞΞΞΞΞΞΞΞΞΞΞΞΞGAME STATSΞΞΞΞΞΞΞΞΞΞΞΞΞΞ⊱
Draw %: 6%
First Turn Advantage %: 47%
Time taken %: 0.02179s
As you can see the win/loss ratio for both players is pretty much even. Makes sense because they are literally employing this strategy:

Which is more or less effective? I mean if it works it works.
Minimax algorithm
Normally people aren't randomly deciding their moves. There are calculations behind every move you make especially in a game where there are clear winners and losers. If we want to go beyond the human performance of this model, we should employ some algorithms that will maximize our potential to win.
The first of the algorithms is the minimax algorithm. The theory behind this is that the opponent will always try to minimize the value that the minimax algorithm is trying to maximize. Thus, the computer's next move will be the one where the opponent can do the least amount of damage.66
Steps
Step 1: Build a Game Tree
Because the minimax algorithm is a backtracking algorithm, it will build on a solution, and then discard a candidate that cannot possibly be valid, we need a tree that represents all possible moves from the current game state.
Step 2: Evaluate Terminal States
For all possible terminal states of the game, we assign a utility value to those terminal nodes. The utility function that will be used for both this algorithm and the next will be:
Utility = # of stones in max(mancala) - # of stones in min(mancala)
Step 3: Propagate utility upwards
Starting from the terminal nodes, use the utility function to determine which nodes are selected.
- If it's the maximizing player's turn, we select the max value from the child nodes.
- If it's the minimizing player's turn, we select the minimum value from the child nodes.
Step 4: Select the optimal move
At the root of the tree, the max player selects the move that leads to the highest utility value.
The final algorithm would look something like this:
def minmax_decision(game, depth=4):
player = game.current_player
def max_value(depth):
if depth == 0 or game.winning_eval():
return game.utility(game.board, player)
v = -np.inf
for a in game.actions():
undo_info = game.play_with_undo(a)
v = max(v, min_value(depth - 1))
game.undo_move(undo_info)
return v
def min_value(depth):
if depth == 0 or game.winning_eval():
return game.utility(game.board, player)
v = np.inf
for a in game.actions():
undo_info = game.play_with_undo(a)
v = min(v, max_value(depth - 1))
game.undo_move(undo_info)
return v
best_score = -np.inf
best_action = None
for a in game.actions():
undo_info = game.play_with_undo(a)
value = min_value(depth - 1)
game.undo_move(undo_info)
if value > best_score:
best_score = value
best_action = a
return best_action
Results
When we run a Minimax agent against a Random Agent, these are the rough stats for 100 games:
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 1 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P1 win %: 90%
P1 loss %: 7%
Avg turns per game: 17
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 2 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P2 win %: 7%
P2 loss %: 90%
Avg turns per game: 17
⊰ΞΞΞΞΞΞΞΞΞΞΞΞΞΞGAME STATSΞΞΞΞΞΞΞΞΞΞΞΞΞΞ⊱
Draw %: 3%
First Turn Advantage %: 44%
Time taken %: 5.48493s
The gameplay has improved significantly. The Minimax agent (P1) is winning about 9/10 games and the Random agent is still throwing darts blindly.
Alpha-beta pruning
This next algorithm is similar to the minimax algorithm, which I mean it is the exact same algorithm just more optimized. The alpha-beta pruning works by essentially removing the child nodes that cannot possibly affect the final decision, which avoids unnecessary computation.
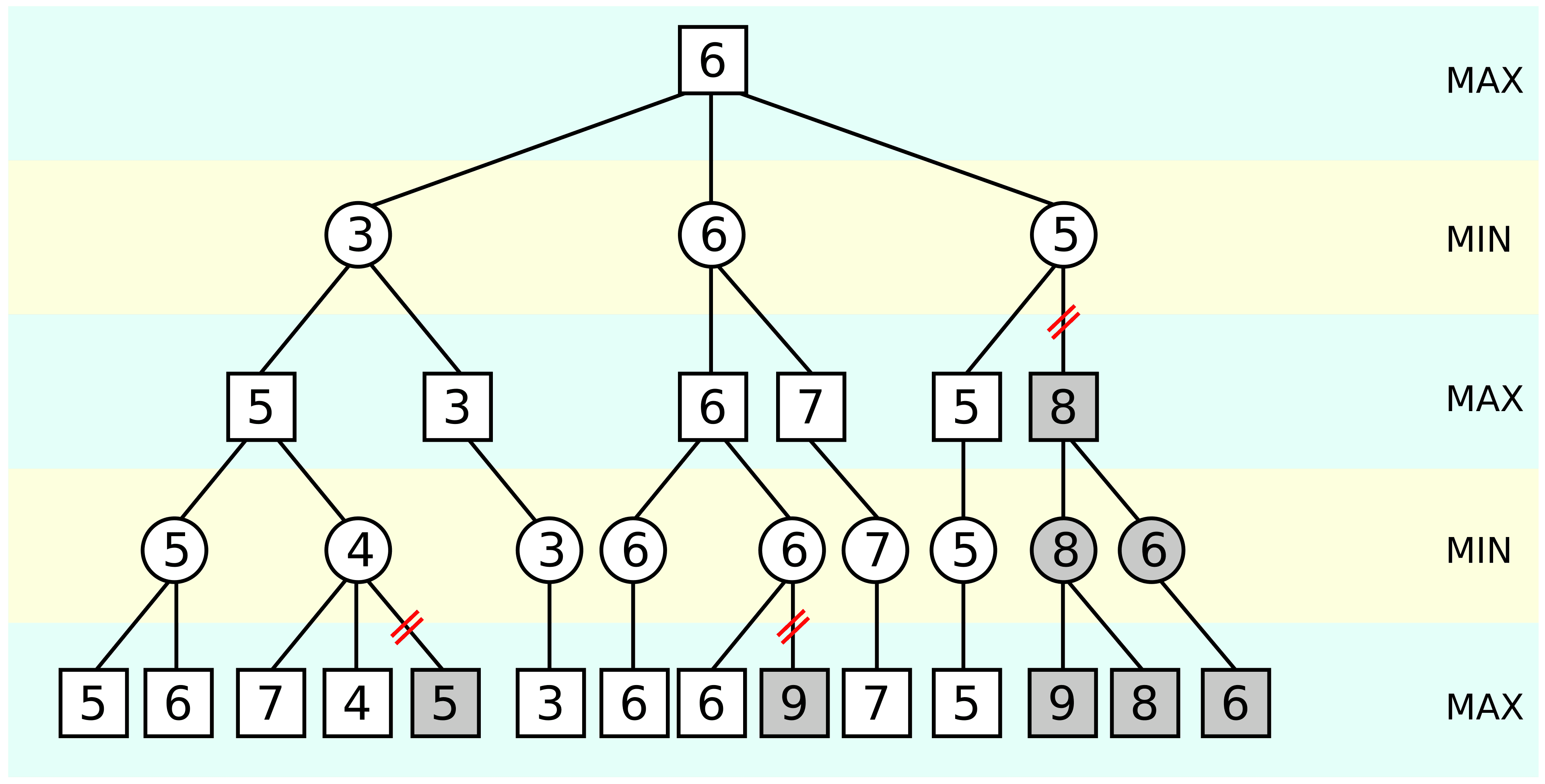
Steps
AB pruning works similar to Minimax with the addition of two maintained values: alpha (a) and beta (b)77
Step 1: Initialize 'a' and 'b'
a = -infty b = +infty
We use infinity to represent the worst possible scores for both the maximizer and minimizer.
Step 2: Max node evaluation
For each child of a Max node, we recursively evaluate the Minimax algorithm and update alpha:
a = max(a, value)
If at this point a >= b stop evaluating the remaining children.
Step 3: Min node evaluation
For each child of a Min node, we do the same thing:
b = min(b, value)
If at this point b <= a, stop evaluating the remaining children.
The final algorithm used in the Mancala game looks something like this:
def alpha_beta_search(game, depth=4):
player = game.current_player
def max_value(alpha, beta, depth):
if depth == 0 or game.winning_eval():
return game.utility(game.board, player)
v = -np.inf
for a in game.actions():
undo_info = game.play_with_undo(a)
v = max(v, min_value(alpha, beta, depth-1))
game.undo_move(undo_info)
if v >= beta:
return v
alpha = max(alpha, v)
return v
def min_value(alpha, beta, depth):
if depth == 0 or game.winning_eval():
return game.utility(game.board, player)
v = np.inf
for a in game.actions():
undo_info = game.play_with_undo(a)
v = min(v, max_value(alpha, beta, depth-1))
game.undo_move(undo_info)
if v <= alpha:
return v
beta = min(beta, v)
return v
best_score = -np.inf
alpha = -np.inf
beta = np.inf
best_action = None
for a in game.actions():
undo_info = game.play_with_undo(a)
v = min_value(alpha, beta, depth-1)
game.undo_move(undo_info)
if v > best_score:
best_score = v
best_action = a
alpha = v
return best_action
Results
When we run our Alpha-Beta agent (with a depth of 10) against our Random agent, after 142 seconds of run-time, we get these results:
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 1 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P1 win %: 100%
P1 loss %: 0%
Avg turns per game: 16
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 2 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P2 win %: 0%
P2 loss %: 100%
Avg turns per game: 16
⊰ΞΞΞΞΞΞΞΞΞΞΞΞΞΞGAME STATSΞΞΞΞΞΞΞΞΞΞΞΞΞΞ⊱
Draw %: 0%
First Turn Advantage %: 51%
Time taken %: 142.27218s
Wow, our AB agent has completely defeated our random player. The random dart throwing did not prove to be successful (doy).
Minimax vs Alpha-Beta
Now that we know the success of both algorithms against a random agent, it's time to PIT THEM AGAINST EACH OTHER:
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 1 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P1 win %: 49%
P1 loss %: 51%
Avg turns per game: 19
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 2 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P2 win %: 51%
P2 loss %: 49%
Avg turns per game: 19
⊰ΞΞΞΞΞΞΞΞΞΞΞΞΞΞGAME STATSΞΞΞΞΞΞΞΞΞΞΞΞΞΞ⊱
Draw %: 0%
First Turn Advantage %: 100%
Time taken %: 7.06747s
That comes at no surprise, because since they are essentially the same algorithm, both would be playing optimally and thus leading to a 50/50 split on wins and losses.
Continuation
Remember the crossed out rule from earlier? If not, here it is again:
- If the last stone you drop is in your own mancala, take another turn immediately
This rule adds more complexity and nuance to Mancala, and drastically changes the strategies used when playing. To implement this rule, we just need to add another function and call it in the play() function for our game:
def continue_play(self, current_index):
if self.continue_turn:
player_mancala = self.p1_mancala_index if self.current_player == 1 else self.p2_mancala_index
if current_index != player_mancala:
self.switch_player()
elif self.print_output:
print(f'{color.YELLOW}Player {self.current_player} gets another turn!{color.END}')
else:
self.switch_player()
With our new continuation rule in place, let's see how Alpha-Beta will fare against a Random agent:
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 1 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P1 win %: 98%
P1 loss %: 2%
Avg turns per game: 18
⊰ΞΞΞΞΞΞΞΞΞΞΞΞPLAYER 2 STATSΞΞΞΞΞΞΞΞΞΞΞΞ⊱
P2 win %: 2%
P2 loss %: 98%
Avg turns per game: 16
⊰ΞΞΞΞΞΞΞΞΞΞΞΞΞΞGAME STATSΞΞΞΞΞΞΞΞΞΞΞΞΞΞ⊱
Draw %: 0%
First Turn Advantage %: 57%
Time taken %: 179.33986s
Swept. It absolutely swept the random agent with no crumbs left behind.
Conclusion
The most obvious conclusion is that if your opponent can see into the future within milliseconds and knows the best possible moves out of all game states, quit that game immediately. All in all, this is a fun way of exploring artificial intelligence through the use of game theory with the intent of taking children's games way too seriously.
This was definitely fun to make and explain, and I hope it either entertained you or gave you insight about search algorithms or even learning what Mancala is! Go forth and become the best Mancala player.